Education Entertainment Companion Robot
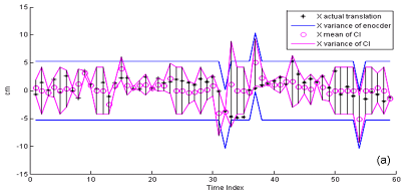
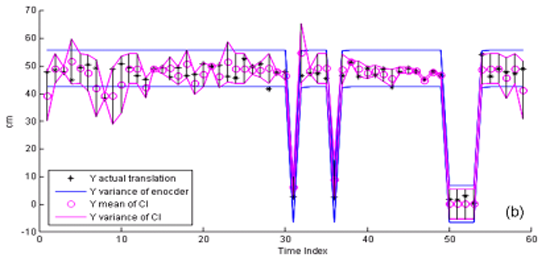
The Covariance Intersection (CI) is a data fusion algorithm which takes a convex combination of the mean and covariance in the information space. This figure shows Covariance Intersection Fusion Result on Robot Pose Translation (a) x-direction (b) y-direction.

ROBOT POSE ESTIMATION
Ultrasonic localization and mapping
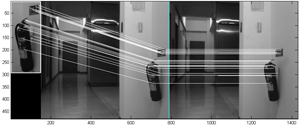
Range Estimation from Stereo Vision Constraints
Visual Tracking
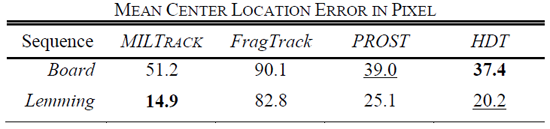
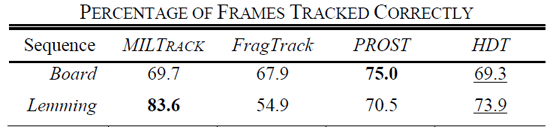
Table 1 Comparison of different trackers. HDT is our tracker.


Hand Recognition
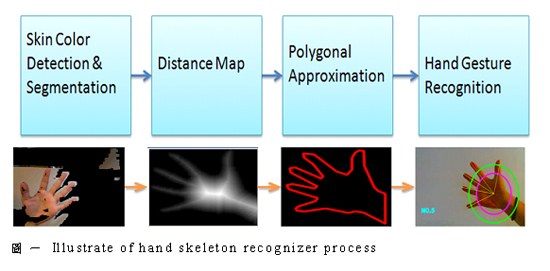
Hand sign recognition is an essential and fast way for Human-Robot Interaction (HRI). Sign language is the most intuitive and direct way to communication for impaired or disabled people. Through the hand or body gestures, the disabled can efficiently let caregiver or robot know what message and order they want to convey. In this thesis, we propose a combinatorial hands gesture recognition algorithm which combines two distinct recognizers. These two recognizers collectively determine the hand’s gesture via a process called Combinatorial Approach Recognizer (CAR) equation. These two recognizers are aimed to complement the ability of discrimination. To achieve this goal, one recognizer recognizes hand gesture by hand skeleton recognizer (HSR), and the other recognizer is based on Support Vector Machines (SVM) equation is devised to synthesize the distinctive methods.
Appearance-based for object recognition is in common use. According to the appearance, it is convenient and accessible way in image processing. Therefore, there are numerous researches for the hand sign, hand gesture and shape recognition by thinning method, contour & curvature, and convex hull based on outstretched hand.

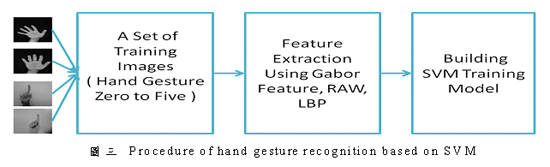
藉由SVM分類的辨識器
利用lib-svm,藉由svm分類器來將影像分類,並且做辨識。在偵測到的影像中找尋特徵點,將特徵點進行分類,建立一個模組。如此一來,當未知的影像輸入時,可以辨識到影像中的手勢為何。圖三為SVM分類的辨識器的流程圖,圖四為辨識的結果圖。

結合辨識器
透過CAR公式,將上述兩種不同型式的辨識器結合所結合出的辨識器。能相互彌補缺點,互相改進,提高辨識的準確度。圖五為結合辨識器的辨識結果。

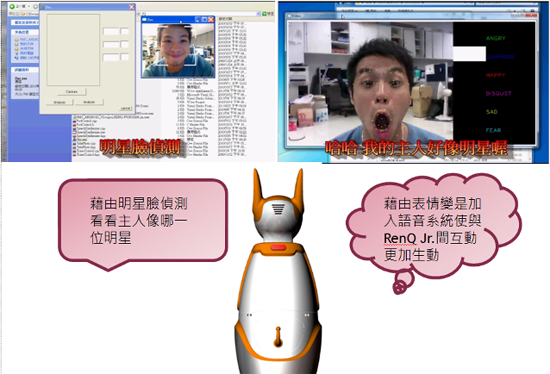
Facial Expression Recognition
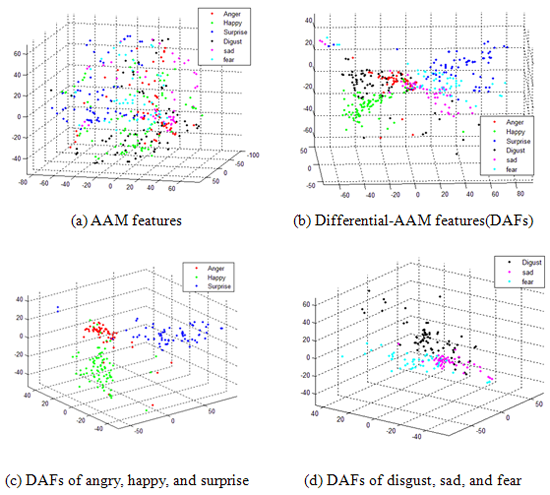
Emotional interaction with human beings is desirable for robots. The objective of this thesis is to implement an integrated system which has ability to track multiple people at the same time, to recognize their facial expressions, and to identify social ambiance. Consequently, the intelligent robot with vision systems can acquire the information of the ambient atmosphere and further interacts with people properly. Optical flow and component-based active appearance model are applied for facial features alignment and tracking. In our facial expression recognition scheme, we fuse Feature Vectors based Approach (FVA) and Differential-Active Appearance Model (AAM) Features based Approach (DAFA) to obtain not only apposite positions of feature points, but also more information about texture and appearance. With the obtained useful information, FVA can classify the emotions according to comparison with the distances and ratios of feature points, and DAFA can distinguish emotions from classical machine learning on a low dimensional manifold space. Furthermore, emotion recognition of multiple people at the same time is extended. Based on the proposed algorithm, multiple person emotion analysis and social ambient atmosphere identification can be achieved, which makes the relationship between people and robots much closer.
影像特徵的萃取Image Features and Descriptors
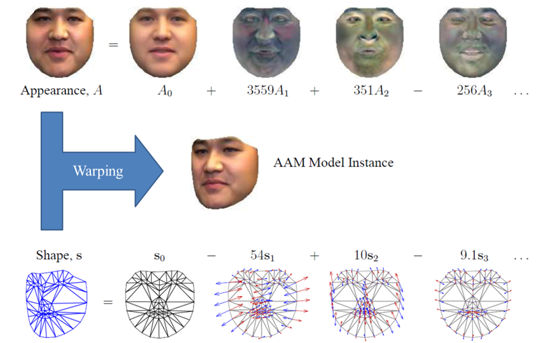
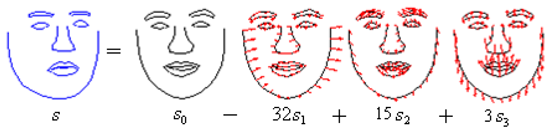
下圖為AAM model instance,並說明了 DAF比起AAM的feature 有較高的辨別效果。
表情辨識Algorithm of Facial Expression Recognition
AAM則是利用分離資料圖庫中人臉的texture及shape,分別當成向量,由PCA演算法得出eigenvectors,然後再藉由一連串的iteration來調整重組這些eigenvectors的比重。

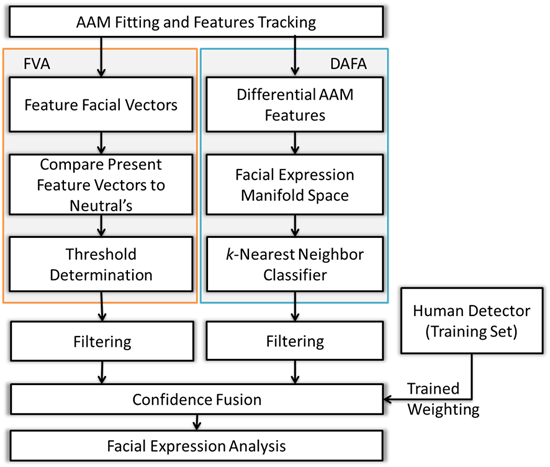
Combining two different approaches, FVA and DAFA, a statistical weighting was employed to a voting scheme based on the linear discrimination function which is shown in the flow chart below.
表情辨識系統主要結合兩方法: Feature Vectors based Approach (FVA)與Differential-AAM Features based Approach (DAFA)。FVA分析臉部特徵點的幾何距離與比例,DAFA在manifold space 中分析differential-AAM features而此特徵包含光影與臉部紋路等等。經由fusion後,可以得到較高的辨識率。下圖為主要的流程圖及實驗結果。

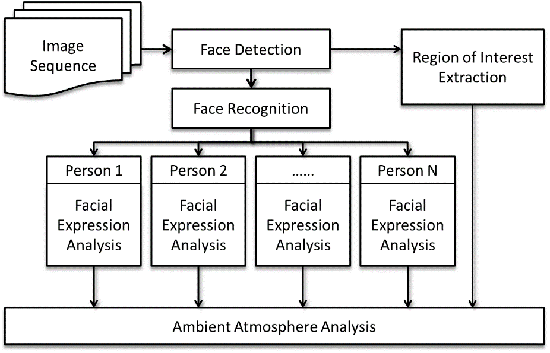
Ambient Atmosphere Analysis
下圖為其架構、情境與實驗結果。


Cross-Correlation Algorithm
Sound signal frequency analysis
Sample value = -127~128
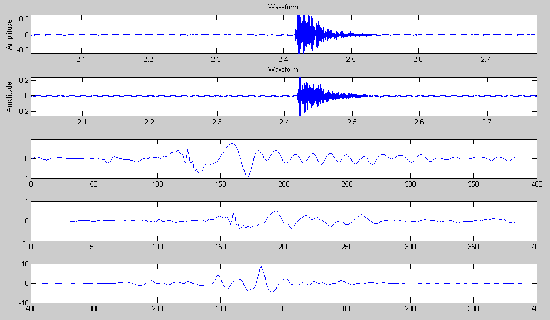
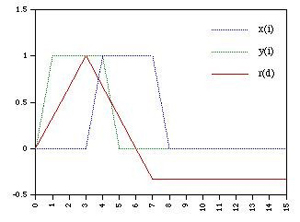
Signal Processing Concept
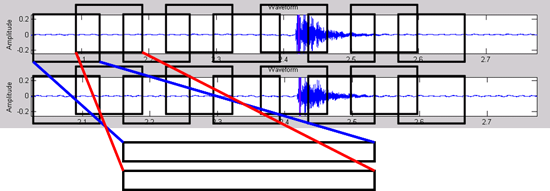
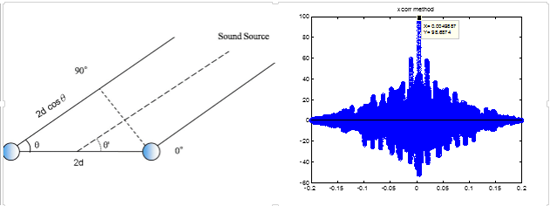
Cross-Correlation


Robot Sound Localization
Kangaroo Robot
Baby Care (Object Tracking)

Gender Recognition(Image Recognition)

CAI (Computer assisted instruction)

Facial Expression Recognition (Image Recognition)