Robot Operating System (ROS)

什麼是Semantic Map
Semantic Map是一種儲存知識的格式,將物體和場景的知識對應到地圖場景中的位置,建立環境和物件之間的關係(圖1.1, 圖1.2),進而能夠提供給機器人在環境中執行較為高階的工作,其中直接使用的模組包括移動機器人在空間中的導航(Navigation)、避障(Collision Avoidance)、定位(Localization)和建圖(Mapping)、機器手臂軌跡規劃(Path Planning);人機互動等。
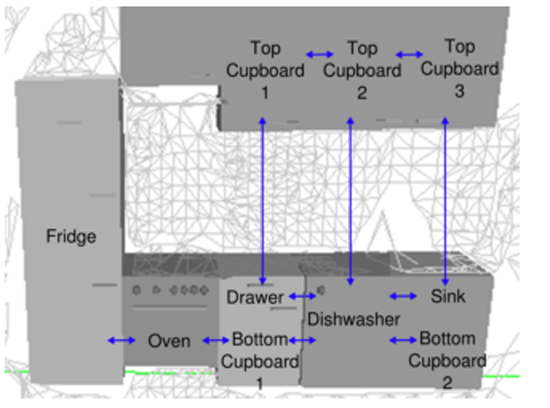
(圖1.1)

(圖1.2)
為什麼我們需要Semantic Map
服務型機器人和工業型機器人最大的差異在於,服務型機器人大多要面對複雜動態變化的環境,而工業型機器人相較之下,多應用於可控制的作業環境之下。因此,服務型機器人對於環境認知的要求,遠比工業型機器人還多,機器人如何在動態的環境中,準確的執行其相關命令,包含路徑規劃、定位、避障、手臂控制等相關應用,都需仰賴好的認知系統來完成。
人類的各種行為背後都包含了知識,如果我們希望機器人有接近人類的行為並能提供適合人類的服務,那麼就讓機器人能夠對於環境有接近人類的認知方式,而Semantic Map就是最接近人類對環境認知的model。
想像如果我們要做一隻有用的機器人可以幫我們打掃實驗室,要能夠掃的好,至少需要實驗室的地圖,然後也需要知道打掃用具在地圖的哪裡,而這兩項元素就是最基本的Semantic map,也就是用地圖的形式來存知識。
實作Semantic Map的平台
ROS機器人作業系統(Robot Operating System)
ROS是一個Open source的機器人開發平台,在這個架構下,讓機器人各大領域Navigation、Manipulation、Perception、Cognition等,建立共通的使用平台,全世界的研究員都可以在這個平台上分享各種機器人相關研究的資源和演算法
今天我們要做一台服務型機器人,有ROS的話就不需要要從頭寫Controller、Driver甚至是3D物理環境模擬器。ROS提供我們一個穩定的模擬測試平台,以及共用各知名大學的研究成果,讓我們可以專注在改善機器人不足的地方,能夠大力發展各大學的專長技術。
目前ROS已支援各式各樣的程式語言,已實做且驗證穩定的的包括C++和Python;實驗性的程式庫,也就是已經提供該種程式語言相對應的Client Library,但並未驗證Stable,包括Lisp、Octave、Java等。
PR2硬體(Personal Robot 2)
PR2(圖3.1)是由美國Willow Garage公司製造的機器人,PR2機器人提供我們一個穩定的演算法及技術研究之硬體測試平台,讓我們不用處理繁雜的系統硬體架設的問題(圖3.2),可以專注在軟體高級應用功能的開發。

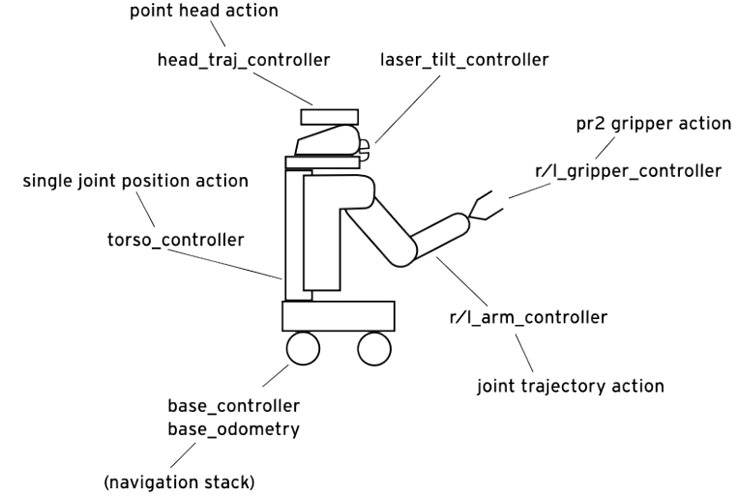
(圖3.1) (圖3.2)PR2硬體結構
實作技術
機器人需要幾個基本功能才能和外界環境互動(圖4.1),包括Perception感之外界環境、Navigation在環境中移動、Manipulation與環境互動、以及儲存知識的資料庫和處理知識與Planning的功能。而這幾個基本功能也正是我們探索外在世界並儲存成Semantic Map表示法所需要的功能(圖4.2)
(圖4.1)移動機器人系統示意圖
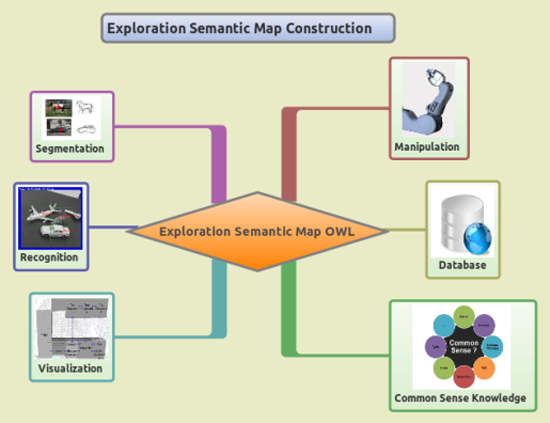
(圖4.2)Semantic模組架構圖
Perception
近年來3D影像感測器漸漸普及,讓我們能夠從視覺感測器獲得環境深度資訊,而處理這種3D影像的重要工具就是Point Cloud Library(PCL)(圖4.3)。PCL主要是透過PointCloud的資料結構來表示3D物體,一般3D model是由mesh貼圖而成,但是PCL的Point Cloud資料結構更適合進行處理。
(圖4.3)
我們實際使用PCL,做到簡單的影像處理功能,如:Segmentation(圖4.4)、Down Sampling(圖4.5)等等。
Segmentation是利用SANSAC的演算法去找到匹配的Model,然後再將場景中匹配的部分切割出來做grouping,就能得到我們想要的部分。
Down Sampling原理則是將PCL切割成許多小方塊,然後以這個方塊內所有點的質心來做代表。

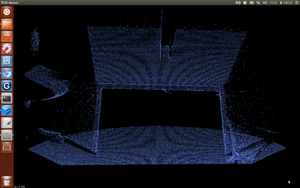
(圖4.4)Segmentation (圖4.5)Down Sampling
取得影像資訊後就要開始進行物體辨識,我們主要使用的模組是Tabletop Object Detector,包括Tabletop Object Segmentation和Tabletop Object Recognition兩部分功能;這個模組適合使用的場景是桌面上對稱物體的辨識。
我們實際使用Tabletop Object Detector的辨識步驟流程如下:首先透過Tabletop Object Segmentation找出最大平面,也就是桌面,然後將平面切除後,就能得到桌面上的物品,然後再將這些切除出來的點做grouping,得出一團一團的PointCloud,切割出來每一團PointCloud就可以交給Tabletop Object Recognition做辨識。
Tabletop Recognition會先將輸入的PointCloud根據對稱的假設做Reconstruction,再將重建過後的Model由PCL和Databse進行特徵點比對,最後回傳一個List,代表辨識出來可能的結果,並包含對於每個可能結果的Confidence。
我們利用ROS提供的Rviz工具,將辨識結果(圖4.6)畫出來,黃色框框就是辨識出來的最大平面,平面上的罐子和酒杯被辨識出來,淺藍色的部分是Database裡Model的形狀,將辨識出來的Model與原始PointCloud影像疊圖,發現兩者匹配得很好,也就是這個辨識的結果令人滿意。


(圖4.6)
Semantic Map Editor
Semantic Map是用OWL文字格式儲存,而Semantic Map Editor是一個讓我們可以編輯,並用視覺化的方式顯示Semantic Map的工具。我們實際載入個現成的Semantic map OWL,開起來後的結果如圖4.7,旁邊有幾個欄位,包括Object Dimension、Object Position、Object名稱等等,也能直接用這個編輯器手動加入物體,修改Semantic Map。
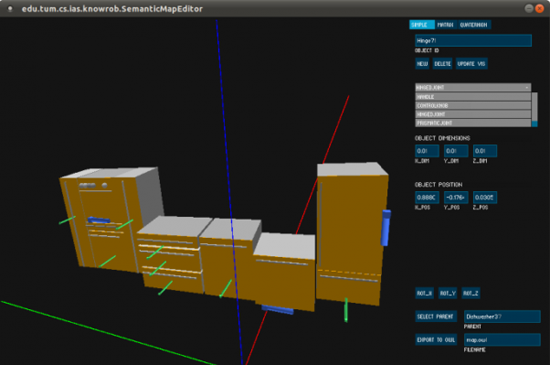
(圖4.7)Semantic Map Editor
Navigation
Gmapping
透過機器人Base Laser掃描環境,可以偵測環境中哪些地方是障礙物,哪些地方是可以走動的,而Gmapping然後透過Rao-Blackwellized particle filer以及Extended Kalman Filter(EKF)的演算法來做機器人的Localization,以及建立地圖。
我們實際建立完整實驗室的地圖是透過遙控機器人的方式,機器人能夠一邊建立地圖(Mapping),一邊進行定位(Localization),最後操縱機器人走完整個房間後,就能建出房間邊緣牆壁以及房間中的障礙物,也就是圖中黑色的部分,而白色的部分就是可以通行的地方,最後成功建立出實驗室地圖(圖4.9)。
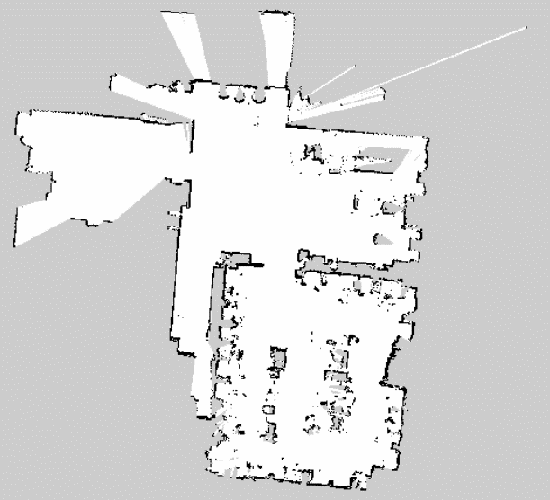
(圖4.9)Gmapping建出實驗室地圖
SLAM+Navigation
如果希望導航時同時建grid map地圖和定位,也就是提供在已經建立的地圖上,進行避障Navigation的功能,則我們可以使用pr2_2dnav_slam這個模組。
pr2_2dnav_slam使用adaptive (or KLD-sampling) Monte Carlo localization approach以及EKF來進行localization和建地圖,在建好的地圖上做Navigation的方式,global planner是先計算出現有地圖的cost map,然後利用Dijkstra演算法找出最短距離的路徑;而local planner是使用Dynamic Window Approach演算法
我們目前已經完成在3D Gazebo動態物理環境模擬器上建立一個環境,然後我們就能在Rviz這個visualizer裡下命令讓機器人移動到我們指定的目標點,在移動的過程能夠一邊展開地圖,並且還能夠規劃出繞過障礙物避障的軌跡(圖4.10)
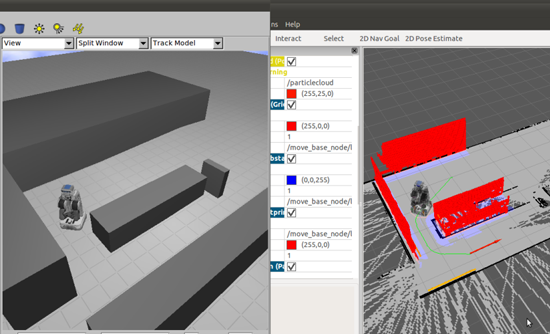
(圖4.10)SLAM+Navigation